(INFOCOM2024) An Elastic Transformer Serving System for Foundation Model via Token Adaptation
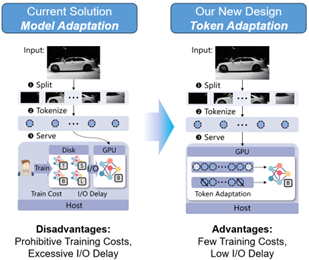
Transformer model empowered architectures have become a pillar of cloud services that keeps reshaping our society. However, the dynamic query loads and heterogeneous user requirements severely challenge current transformer serving systems, which rely on pre-training multiple variants of a foundation model to accommodate varying service demands. Unfortunately, such a mechanism is unsuitable for large transformer models due to the prohibitive training costs and excessive I/O delay. We introduce OTAS, the first elastic serving system specially tailored for transformer models by exploring lightweight token management. We develop a novel idea called token adaptation. To cope with fluctuating query loads and diverse user requests, we enhance OTAS with application-aware selective batching and online token adaptation.
Prototype Overview
We use Python to process the incoming queries and PyTorch to define the neural networks. We build the transformer model with timm library and insert two modules to add and remove the processing tokens at each layer. The system enables users to make a query and register tasks with two interfaces. The Make Query interface processes a query that comprises an image sample and various attributes. The Register Task interface saves the task parameters in the task model list and the corresponding latency and utility values in the task data list.